
Create dockers in Fargate and enable availability schedules
By Sahian Hernández, Infrastructure Analyst at Financial Solutions
Although the topic of dockers is not something new, it has become a tool widely used by companies, what can become something new is the service offered by AWS for the use of dockers and although it has 2 services for it (ECS and EKS), the one we will see this time is ECS with Fargate, which makes ECS more focused on “serverless”.
https://aws.amazon.com/es/fargate/
What is Fargate?
Fargate is a serverless compute engine that works with both Amazon Elastic Container Service (ECS) and Amazon Elastic Kubernetes Service (EKS), eliminating the need to provision and manage servers for Docker workloads.
So why would anyone use Fargate?
The answer is as simple as saying why anyone would use Lambda, the ease and flexibility offered by serverless services saves time configuring servers, operating systems, maintenance, costs, etc., without neglecting important aspects such as security or scalability.
With Fargate you can achieve highly available services, a little cheaper than their “server” counterparts and almost completely automated, workloads in companies.
To start working with Fargate, the first step will be to have a Docker image, although there are ways to work with it directly with Docker Hub, for this guide we will use Amazon Elastic Container Registry (ECR).
Inside a server or a local machine that has Docker and AWS CLI installed, with active credentials and sufficient permissions for ECR, we create the image as shown below:
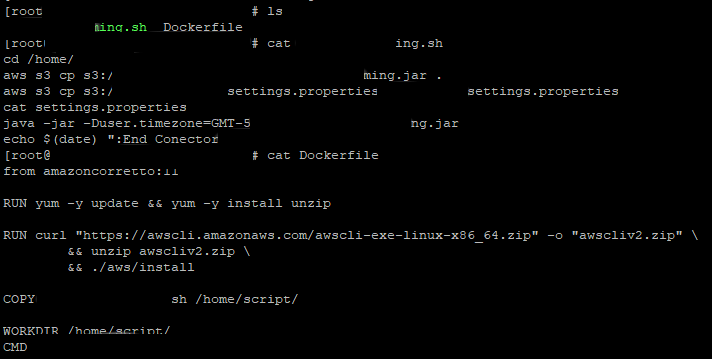
In this example it is composed of a Dockerfile, which contains the definition of the image, in this case an amazoncorretto:11 being this a Docker focused on JAVA and in turn unzip and AWS CLI is enabled in the system.
It also has a script that when executed will go to S3 to search for files, in this case a “.jar” and its configuration file and then run it.
Before creating the image we will proceed to go to ECR and create a new repository, with the desired name in the Docker image:
The other options can be left in default.
Then we enter the repository and click on “view push commands”.

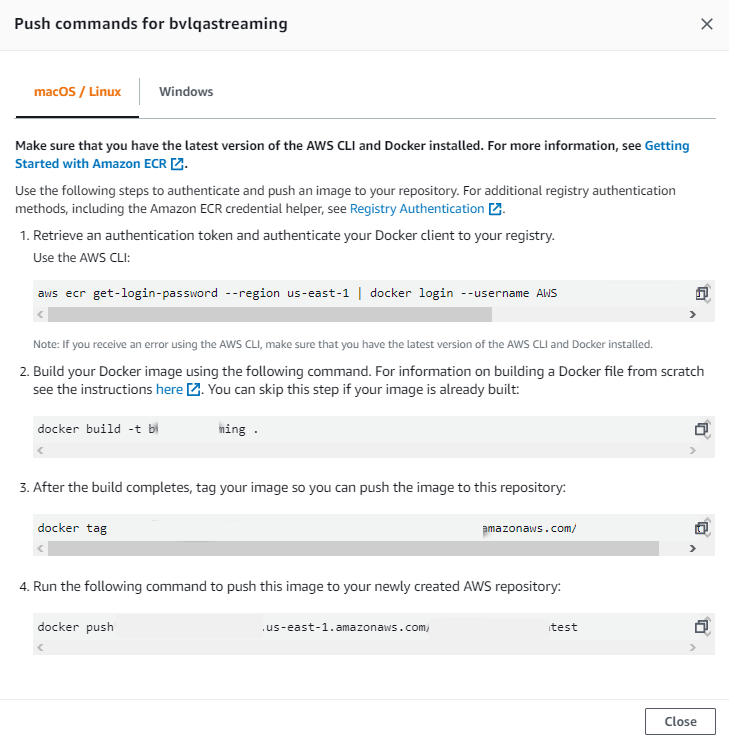
Here we will be able to see several commands, in the same path where the 2 files are or in its defect the corresponding Dockerfile of executing the 4 commands; in case the first one causes problems, it can be substituted by this other one:
· eval $(aws ecr get-login –no-include-email | sed’s | https: // | | ‘)
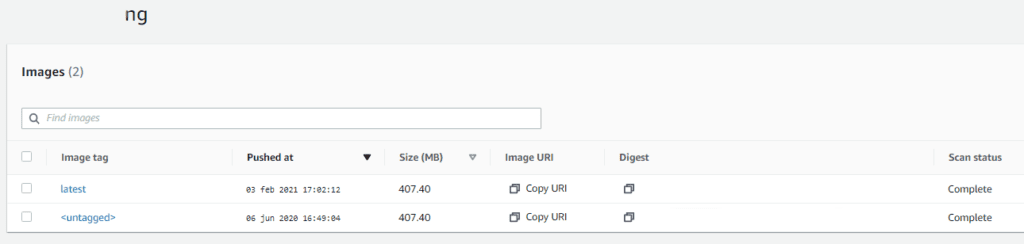
When finishing the 4 commands we will be able to see a version in the repository, later if we create a new one it passes the previous one to “untagged”.
Having finished preparing our initial tools, we are ready to get started with Fargate and in this guide, as previously mentioned, Amazon Elastic Container Service (ECS) will be used.
1. Create a new ECS cluster.
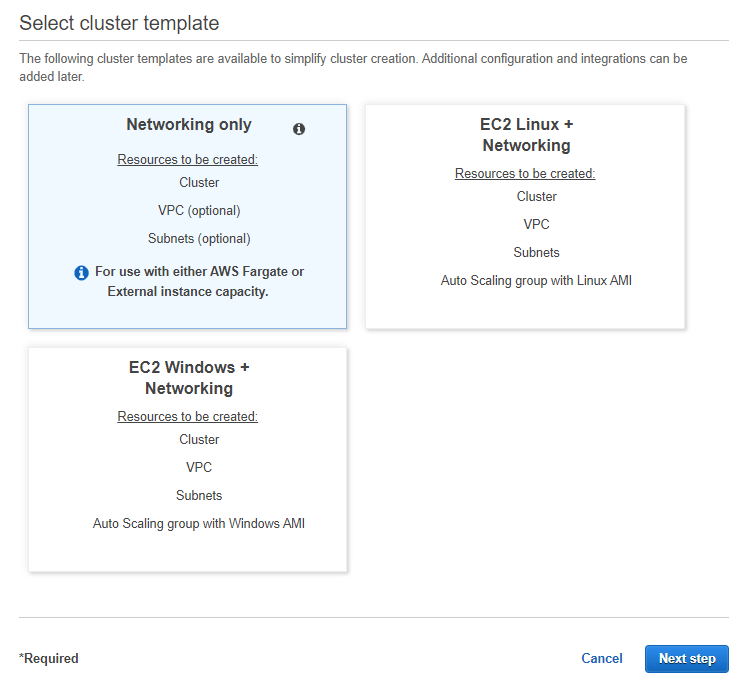
2. Where it gives us different cluster options, choose the one that has in highlighted letters “Powered by AWS Fargate” or “Networking only”.
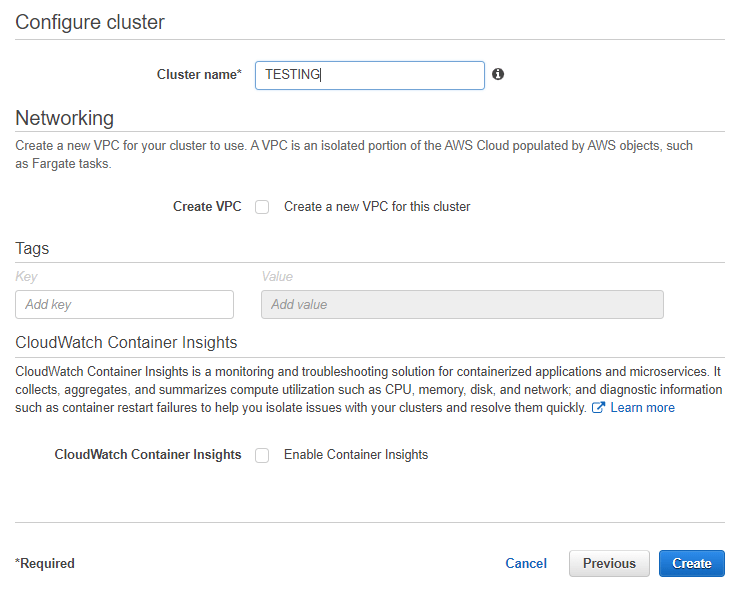
We will put only the name of the Cluster, this is due to the fact that in the account already exist resources like VPC, RDS, SSM, etc and it is sought that the dockers that are created, coexist with those resources, when not putting VPC we will be able to use VPC and Subnets that are in the account.
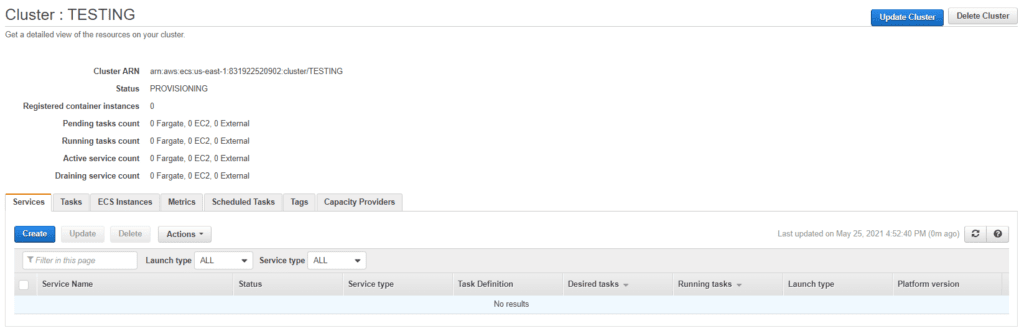
With these 3 steps we will have the cluster created, but before starting to create Dockers, an essential part must be defined; as we saw in the introduction we will not have a server or a conventional place where we will put the image and work with it, so we need to assign the resources it will need, the image to be used, if it needs open ports, special commands, etc.
To do this we will go to “Task Definitions” which is on the left side of our cluster and proceed to create a new “Task Definition”.
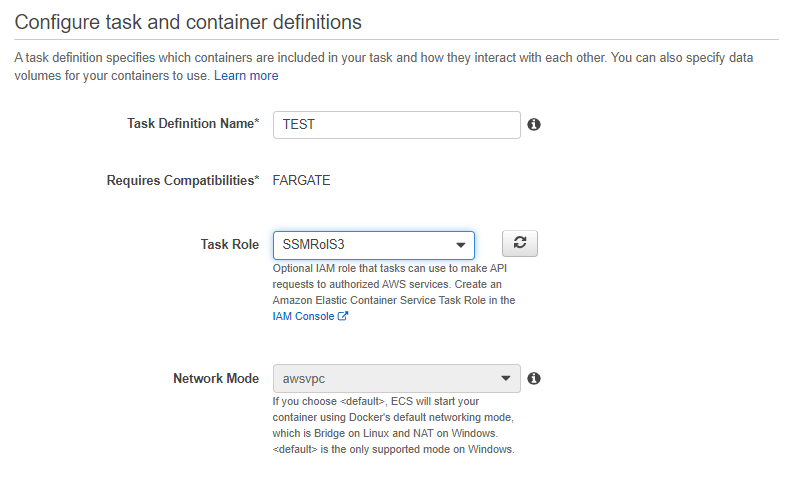
· It will be assigned a name, it is recommended that it is easily identifiable to the ECR image or the same.
· It will be assigned an IAM ROL, there will be one by default that has the necessary permissions to use the ECS resources, to which we will add ECR permissions and in the case of this guide permissions for S3, so the ROL has to be created based on the needs of the image to be used.
· In “Network Mode” leave “awsvpc” .
· In “Requires compabilities” FARGATE is used.
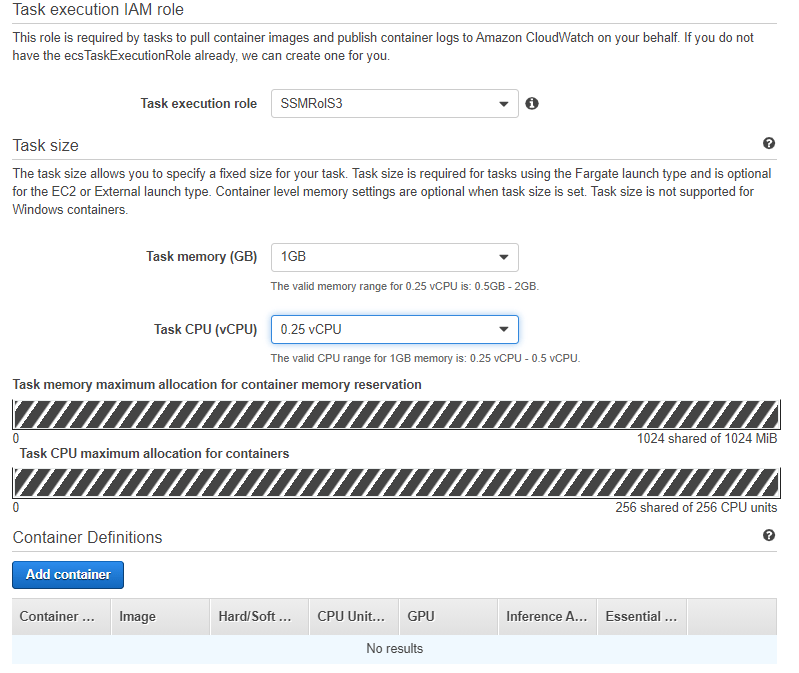
In this section is where Fargate can be “customized” as it allows you to put various combinations of processing, you can assign memory and CPU specialized to the task to be performed, in this example we use 2GB and 0.25 VCPU, but it could be up to 30GB of memory and 4 VCPU.
After assigning the necessary resources, click on “Add container” where we will name the container the “URI” of the ECR image and in turn, we can customize the container for much more specific things that for the moment will not be used.
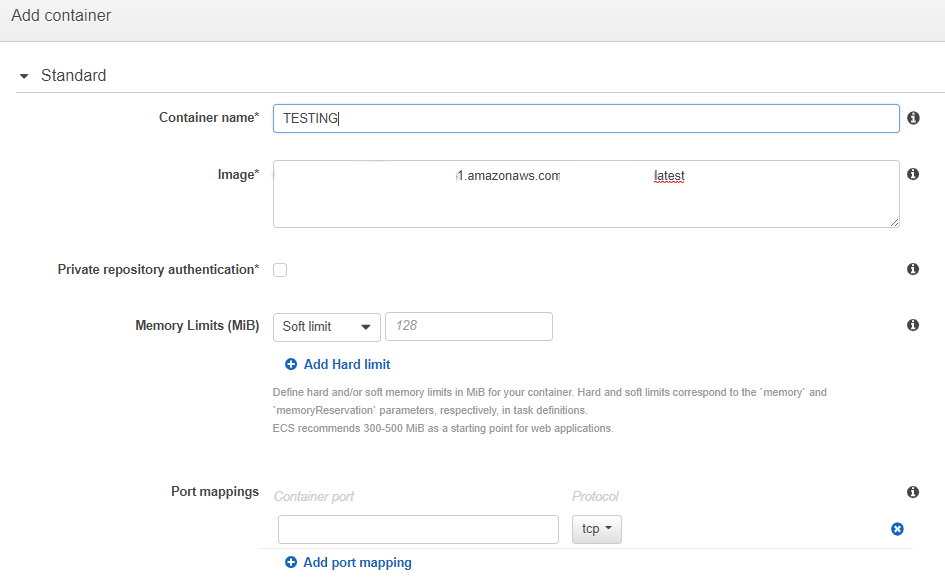
All other options are left as default and the “Task Definition” is created.
At this point we will have everything ready to start creating Dockers, returning to the cluster, we will go to the tasks section and create a new task where we will put:
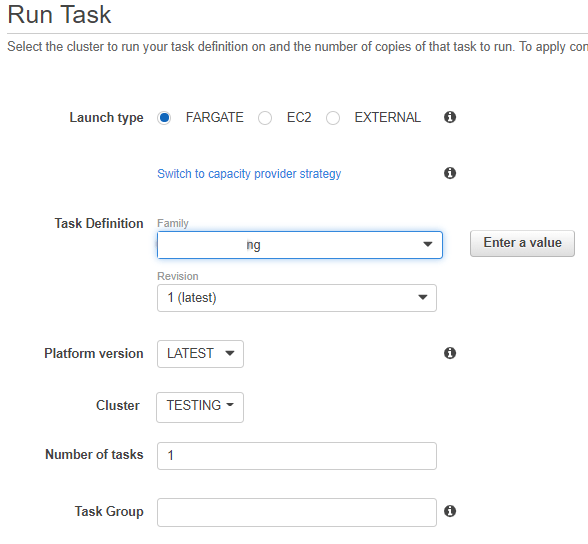
· “Capacity provider strategy” will be Fargate
· Task Definition will be the one previously created together with the revision
· “Platform version” usaremos “LATEST”
· Cluster created
· Number of tasks, as it is a test we will only create 1
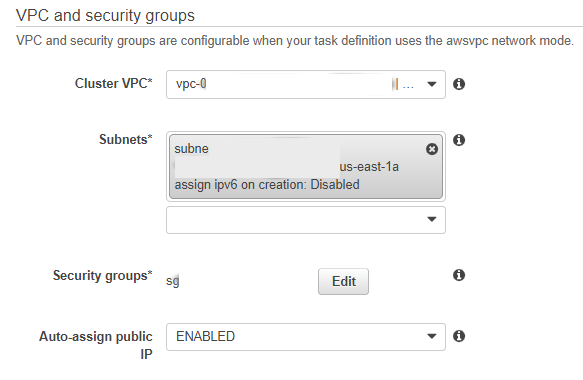
· Cluter VPC allows us to select a VPC inside the account
· Subnets we will choose a subnet inside the VPC
· Security groups a SG that allows us to connect to the resources we need
· Auto-assign public IP us left in ENABLED so that it can reach ECR and bring the image
Click on run and after a few minutes (if everything went well) we will be able to see the Docker running, in case the task appears as “STOPPED”, you can review logs to try to trace the problem.
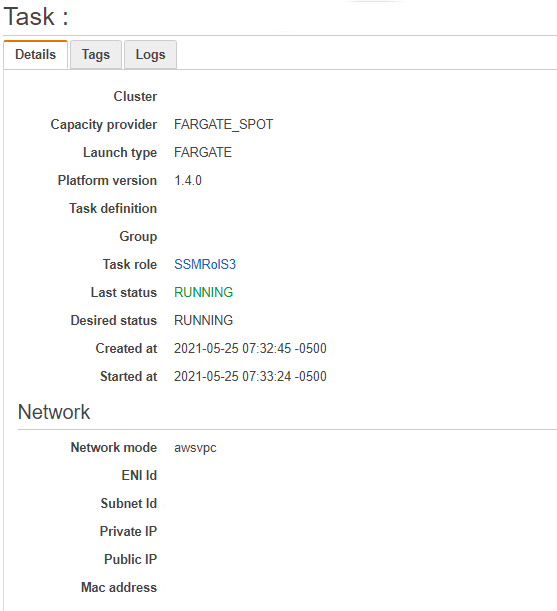
ere is where you can see the information related to it, tags and even the logs it generates, it is also possible to go to Cloudwatch to review the logs in more detail.

At this point Fargate is being used and more tasks can be created depending on the needs, however, when the task is stopped it is “destroyed”, so, if the task is a service that you want always available, creating the task does not do much good.
For these cases ECS can be used to create services, which, in simple words, will be in charge of keeping the tasks in a certain desired number or even many tasks behind some ELB.
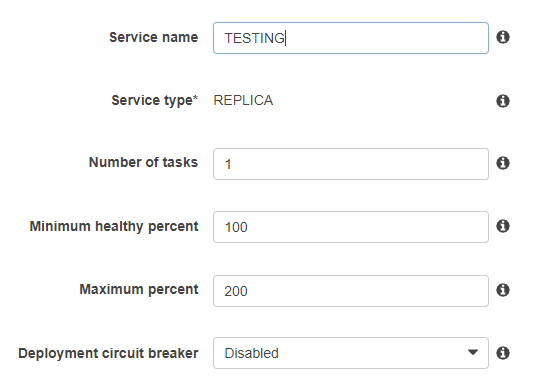
For the creation of the service:
- We will go to services and create a new one where only, it will ask for the name of the service and the same definitions as when executing the “Task”, the other configurations can be left by default since in this example ELB will not be used.

The service will have active tasks based on the “Number of tasks”, if any of them stops, it automatically creates another one to replace it.
Finally, although we already have the service that ensures that the task or tasks are always running, sometimes it is required that the service is only available at certain times, especially in testing environments. To solve this, a viable option would be to perform an execution that makes our service go from 1 to 0 or viceversa, which would virtually “turn on or off” the service, for this we could use lambda with the following configuration:
· Phyton 3.7
· 128 MB
· Timeout 5 seg
lambda_funtion.py:
import boto3
import pprint
import os
region = ‘us-east-1’
client = boto3.client(‘ecs’, region_name=region)
def lambda_handler(event, context):
lambda_realone(event, context);
def lambda_realone(event, context):
response = client.update_service(
cluster=’NOMBRECLUSTER’,
service=’NOMBRESERVICIO’,
desiredCount=1,
deploymentConfiguration={
‘maximumPercent’: 200,
‘minimumHealthyPercent’: 100
},
forceNewDeployment=True
)
Only the name of the cluster and the service and wether you want to turn it on or off are replaced.
Note: if the service needs more than 1 task at a time, the desired number of tasks must be entered.
In this way a lambda for “onECS” and “offECS” would be created, in order to be able to create rules in Cloudwatch.
These rules will allow to execute an “on” at a desired time by calling the on lambda and an off at a different time by calling the off lambda.
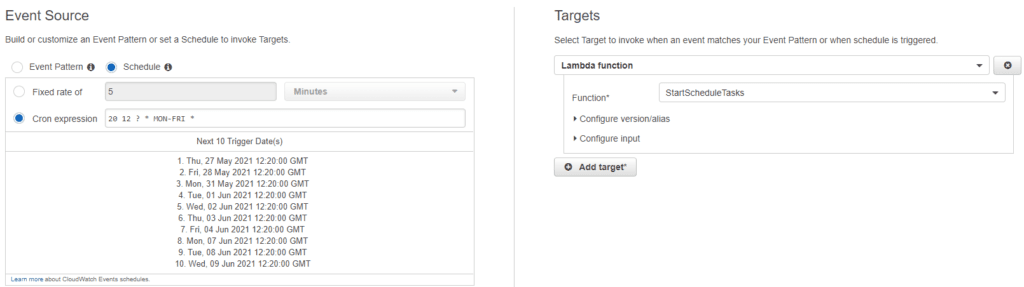
In this way you can achieve a schedule of use of ECS, it should be noted that ECS or Fargate does not charge for having a Cluster created or for services or “Task definitions”, it only charges for the processing used, which is lower than using EC2 normally and can be lowered even more if you use FARGATE_SPOT.
At Financial Solutions we care about always being at the forefront, we work hand in hand with our partners certifying us to offer you a competitive advantage and a high technological standard.
Let me know if this guide helped you and which ones you would like to read more.
Related Post



Recent Posts





